(This is a follow up post to the most-read article I’ve ever written on this blog, SAFe is not Agile.)
Last year, during an engagement with an insurance company, I worked with the product leadership team to understand why their 8-month AI initiative had stalled. They’d assembled a dedicated AI working group, ran three PI planning cycles where AI use cases were formally assigned to Release Trains, and produced a 21-slide deck explaining their AI strategy.
They had not shipped a single AI-powered feature.
The working group was waiting on the Q3 plan to be ratified before beginning experimentation. The Release Trains were waiting on the working group’s recommendations. The 21-slide deck was in review with the PMO.
This wasn’t negligence or laziness. This also wasn’t a technology problem. This was SAFe working exactly as designed.
The Original Bargain
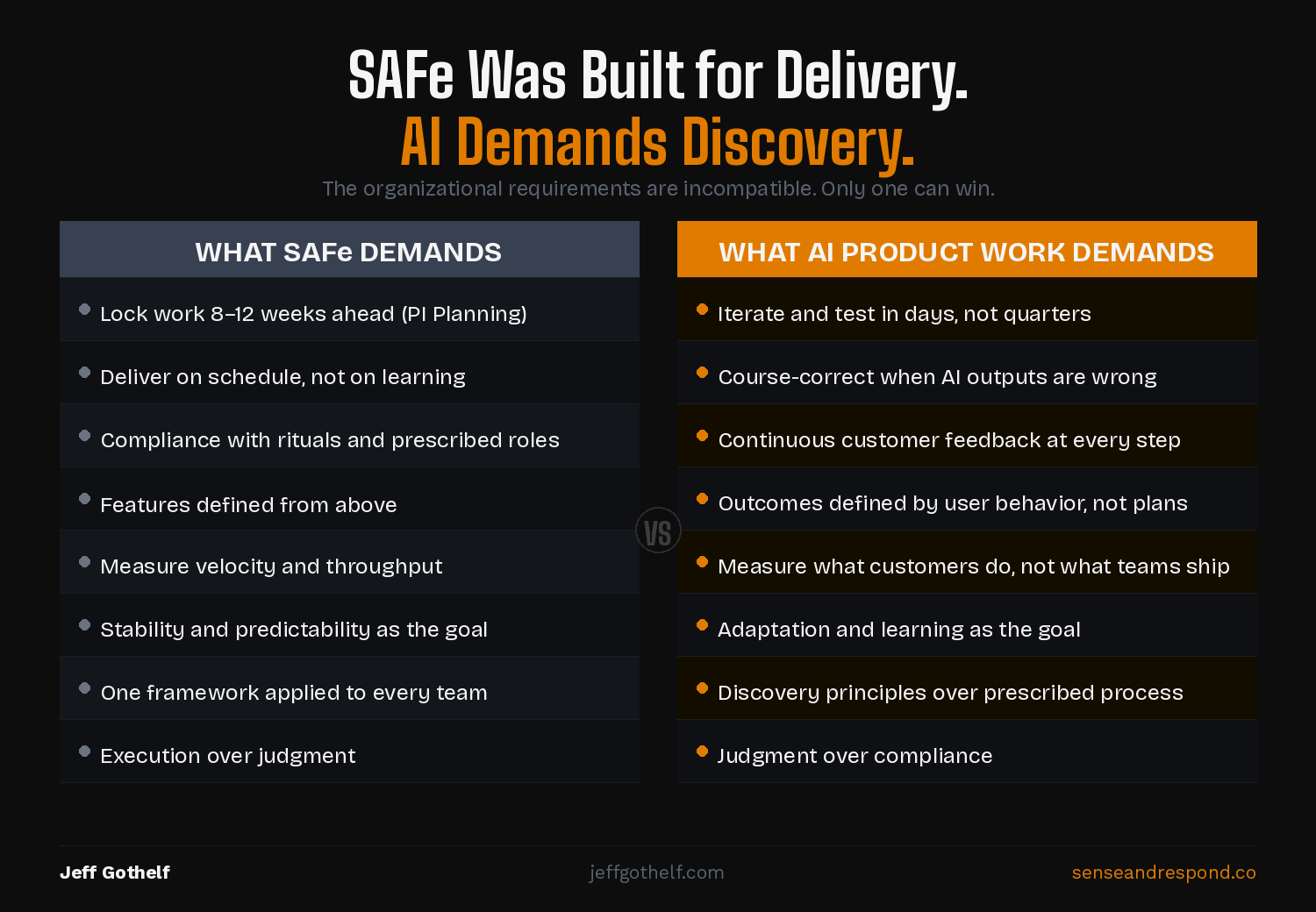
SAFe — the Scaled Agile Framework — was built to solve a real problem: large organizations struggling to coordinate software delivery across dozens of teams. The answer was structure — quarterly PI planning, synchronized Release Trains, coordinated milestones. Predictability was the product. And it worked (oh boy did it work), for delivery.
But even before AI arrived, the cost of SAFe’s rigidity was real and obvious. I wrote about this a few years ago. SAFe optimizes for predictability, and predictability doesn’t react well to learning. Teams that adopted SAFe got better at shipping what they planned. They got worse at discovering what was worth building.
Most organizations accepted that tradeoff. Learning was hard to measure. Delivery was easy to report and therefore manage. And as long as the software worked reasonably well, the cost of not learning felt abstract.
In the AI era, it isn’t abstract anymore.
What AI Actually Demands
AI development doesn’t just require iteration. It requires a fundamentally different relationship with being wrong.
When you deploy an AI feature, you don’t know if it worked well at scale. The model might behave differently with real users than in testing. The outputs might be accurate but unusable. The thing you thought customers wanted turns out to be the thing they ignore. This may sound familiar and that’s because it is. You need to find out fast, adjust, and find out again. This is product management and product discovery work.
Three specific SAFe mechanisms make this nearly impossible.
PI planning locks in work too far ahead. A quarterly planning cycle assumes that what you’ll build in Q3 is knowable in Q1. AI development doesn’t work that way. You learn what to build next by watching what the model does with real users, in real conditions. By the time PI planning gives you permission to change direction, you’ve shipped three months of the wrong thing.
Release Trains reward predictability over pivoting. The Release Train structure is designed to keep teams moving in the same direction at the same time. It penalizes the teams that say “we need to stop and rethink this.” In AI development, those teams are often doing the best or at least the most important work. They’re the ones that notice the model producing biased outputs, or that users were ignoring the recommendations, or that the training data didn’t reflect actual behavior. SAFe’s coordination mechanism punishes exactly the judgment calls AI demands.
The absence of continuous discovery means teams can’t tell when an AI output is wrong. Ongoing, embedded, continuous discovery is the mechanism that keeps you honest about what customers actually experience. Without it, you’re guessing. SAFe doesn’t require discovery. It often makes discovery logistically impossible — teams are too consumed by PI planning ceremonies to talk to users consistently. Add in the pace with which you can collect and analyze feedback in the AI era and you can quickly see that this way of working is an anchor to your competitiveness and relevance in the market.
This Is an Architecture Problem
Let me be super clear. I’m not saying that people working inside SAFe organizations are lazy or naive. They are not. The team at that insurance company cared deeply about shipping AI features. They wanted to do good work. They were frustrated. They could see clearly that the structure wasn’t working.
But with SAFe the structure is the point.
SAFe was architected deliberately to produce predictability and coordination at scale. That was the right answer to the problem it was solving. The problem now is different. AI requires rapid hypothesis testing. It requires continuous discovery. It requires super tight collaboration between product, design and engineering. It often requires skipping certain steps that were once held sacred. And it requires the organizational courage and psychological safety to say “this output is wrong and we need to pivot” in week three, not quarter three.
SAFe was built to make exactly that kind of behavior structurally difficult.
You can’t fix this with an AI working group or a 21-slide deck. You can’t run a PI planning ceremony and then claim your teams are building with agility. You can’t have Release Trains and expect your teams to course-correct on AI outputs in real time.
This is an organizational architecture problem. And SAFe baked and hardened that architecture in deliberately.
If you’re inside a SAFe organization being asked to “do AI,” ask yourselves: When’s the last time your team changed direction based on something an AI model did in production — not in testing, but in production, with real users?
If the answer is “we haven’t done that yet,” it’s worth asking whether SAFe is the reason why.





Leave a Reply